about me
Han Fang is an AI Research Scientist at Meta’s Superintelligence Labs, working on recursive self improvement research and more broadly agentic capabilities. He founded Meta AI’s production post-training team and led production post-training for Llama 2 and Llama 3. He launched Meta AI in 2023 and scaled it to 1 billion MAU — driving integrated training runs, core capabilities, tool use, and data flywheel. Most recently, he is a core contributor to Agents in Muse Spark — developing self-improving agents that can recursively improve model’s agentic capabilities, reaching SoTA on MCP-Atlas and frontier on Toolathlon, and APEX-Agents.
Han holds a PhD in Applied Mathematics & Machine Learning, published in top-tier venues with 12K+ citations. He is a recipient of the President’s Award to Distinguished Doctoral Students, the Woo-Jong Kim Dissertation Award, and the Excellence in Research Award.
Google Scholar / CV / Linkedin / Twitter
news
Autodata: Automatic Data Scientist
2026AI agents that function as data scientists, iteratively building high-quality training and evaluation datasets. Agentic Self-Instruct converts inference compute into better data. Paper · Blog
Muse Spark Agents
2026Drove research to develop self-improving agents that can recursively improve model's agentic capabilities — SoTA on MCP-Atlas, frontier on Toolathlon, and APEX-Agents. Natively multimodal reasoning with tool-use and multi-agent orchestration. Muse Spark · Muse Spark 1.1 · Eval Report
Meta AI reached 1 billion MAU
2025Improved Meta AI's multilinguality, enabled roll-out to 12 languages and 40+ countries. Blog · News
Earlier
- 2024 Launched voice mode and photo editing in Meta AI · Blog
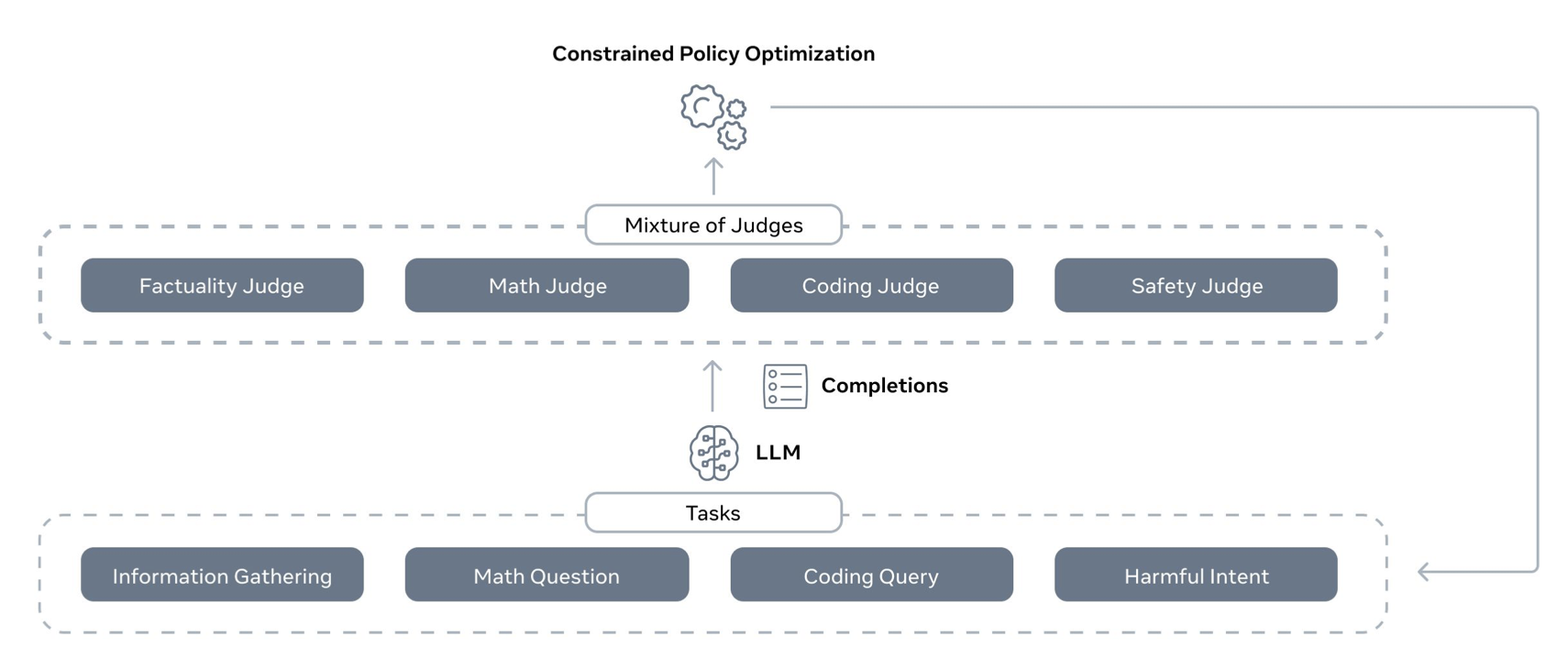
- 2024 Launched Llama 3 on Meta AI · Mixture of Judges · Blog
- 2023 Launched Meta AI with Llama 2 · Meta AI · Talk at Connect
- 2021 Meta AI Few-Shot Learner (FSL) · Blog
- 2020 Training AI to detect hate speech · Blog
blog
The Central Dogma of Artificial Intelligence
February 2026
Every mature science has its central dogma. Biology has DNA → RNA → Protein. What is ours? Intelligence is the compression of experience into generalization.
The RL Environment Field Guide
January 2026
A practical guide to RL environments using Pokemon Red as a case study. Covers the agent-environment loop, observation spaces, reward design, and credit assignment.
Post-training 101: A Hitchhiker's Guide
September 2025
A comprehensive guide to post-training techniques for LLMs, covering supervised fine-tuning, RLHF, reward models, and practical implementation details.